Mariadb metadata lock으로 인해 발생한 장애 회고
Header
운영중인 데이터베이스 테이블에 인덱스를 생성하는 과정에서 대상 테이블에 접근하는 세션들이 쿼리를 실행하지 못하는 상태로 지연되어 20분 정도 서비스가 중단되었던 장애를 회고해보고자한다.
Body

개발과 운영 데이터베이스의 스키마를 비교하던 중 테이블에 생성된 인덱스가 동일하지 않아 운영 데이터베이스에서 누락된 인덱스를 생성하고자 하였다. 인덱스 생성 대상 테이블은 업체의 계약 정보와 관련된 테이블인데 조회가 빈번하게 일어나는 테이블이고 전체 카운트는 1700개 정도이다.
해당 인덱스를 생성하는 작업은 online DDL(inplace)이 지원되기 때문에 운영 중에 서비스 중단 없이 수행이 가능하다. 대상 테이블의 전체 카운트가 많지 않아 짧은 시간 안에 처리될 수 있고 DML이 거의 발생하지 않아 DDL 수행 중에 발생한 DML의 데이터 변경을 저장하는 row log buffer가 초과할 우려가 없다고 판단하여 운영중에 수행하게 되었다.



master DB에서 DDL을 수행하였고 빠르게 처리된 것을 확인했지만 인덱스 생성 DDL을 수행한 후부터 일부 API 요청들의 응답 시간이 지연되었고 504 gateway-timeout 응답이 빈번하게 발생하기 시작했고 결국 지연이 지속되면서 전체 서비스에 장애가 전파되었다.
에러 로그를 확인해 보니 애플리케이션에서 지정한 timeout(1m)보다 응답이 지연되고 있었고 데이터베이스 커넥션 풀에서 지정한 timeout(30s)안에 커넥션을 할당받지 못해 예외가 발생하는 요청도 있었다.


데이터베이스에서 문제가 발생한 것으로 판단하여 상태를 확인해 보니 master DB의 지표에서는 별다른 이상이 없었지만 slave DB의 지표에서만 활성 커넥션과 복제 지연이 급격하게 상승한 것을 확인했다.
원인 파악보다는 우선 서비스를 정상화하기 위해서 팀에서는 문제가 발생하는 애플리케이션들을 재기동하면서 slave DB로 라우팅 되는 요청의 절반을 master DB로 라우팅 되도록 가중치를 변경하고 인덱스를 생성한 대상 테이블에 접근하는 세션들이 metadata lock을 획득하지 못해 지연되고 있는 것으로 확인되어 지연이 발생하는 커넥션들을 강제로 kill 하였다.
하지만 서비스는 정상화되지 않았는데 인덱스 생성 DDL로 인해서 장애가 발생했을 수도 있겠다고 생각되어 팀원들에게 이 사실을 공유하였고 slave DB가 조금이라도 빨리 정상화될 수 있도록 로컬에서 데이터베이스에 접속한 클라이언트의 커넥션도 종료시켰다.

이후부터는 커넥션들의 지연이 해소되어 대기 중인 쿼리들이 모두 수행되었고 서비스가 정상화되었다. 지연이 해소되면서 대기중 이던 쿼리들은 슬로우 쿼리 로그에서 확인할 수 있었다. 하지만 장애가 발생한 원인을 모르는 상태였고 왜 slave DB에서만 문제가 발생했는지도 알 수 없었다. 원인을 파악하기 위해서 metadata lock에 대해서 조사하기 시작했다.
metadata lock은 락을 통해서 데이터베이스 개체(프로시저, 함수, 테이블, 트리거 등)에 대한 동시 요청을 관리하고 데이터 일관성을 보장한다. 트랜잭션(비트랜잭션 포함)에서 접근 중인 테이블은 스키마 변경을 방지하기 위해 metadata lock을 획득하게 되는데 DDL을 수행하기 위해서는 metadata lock이 필요하다. 즉 DDL 수행 대상의 테이블을 접근하는 트랜잭션이 종료되기 전까지는 DDL 수행이 대기하게 된다.
그렇다면 왜 DDL만 지연되지 않고 모든 쿼리들이 지연되는 것인가? online DDL은 각 단계에서 필요한 metadata lock을 잠시 동안 획득해야 하기 때문에 DDL 수행 대상 테이블을 접근하는 트랜잭션이 종료되어 락의 획득할 수 있을 때까지 대기한다. 락의 획득을 대기하고 있는 세션이 여러 개인 경우 우선순위가 가장 높은 요청이 먼저 충족되며 쓰기 잠금 요청은 읽기 잠금 요청보다 우선순위가 높게 설정되어 우선순위가 높은 쓰기 잠금 요청인 DDL을 처리하기 위해 후행 트랜잭션들이 대기하게된다.
그렇다면 락을 획득한 트랜잭션이 종료되지 않아서 지연된 것으로 볼 수 있는데 애플리케이션에서는 장애가 발생할 정도로 트랜잭션을 길게 사용하는 부분은 없었다. 혹시 개발자의 로컬 개발 환경에서 락을 점유하고 있었는지 의심되어 확인해 보니 역시나 맞았고 심지어 범인은 나였다(자폭)… 😭
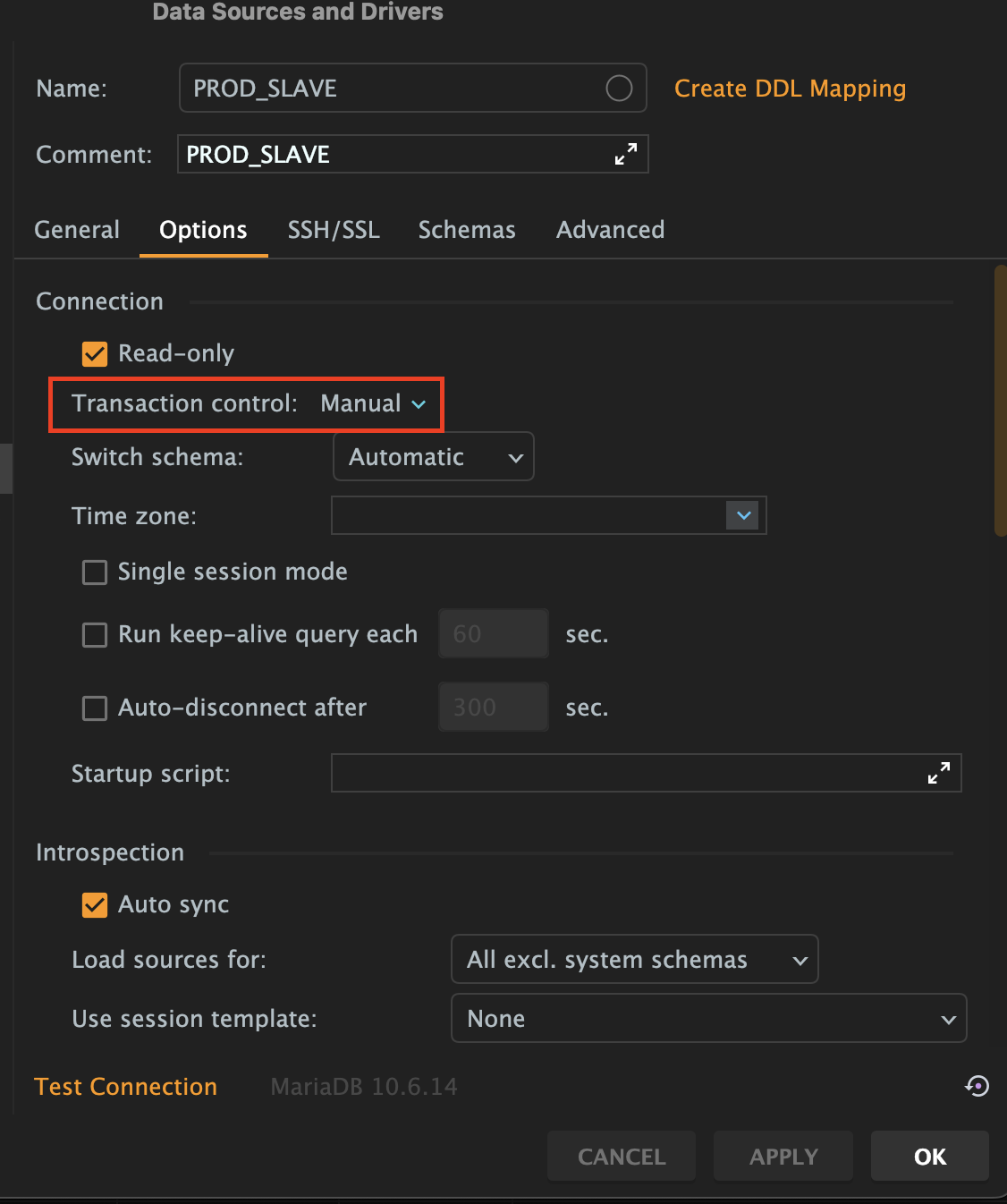
사내의 백엔드 개발팀에서는 Datagrip을 사용하고 있고 공통된 설정을 컨플루언스에 공유하여 사용하고 있다. 온보딩 과정에서 공유된 Datagrip 설정을 import하고 지금까지 사용 중이었는데 확인해 보니 slave DB의 transaction option이 manual로 설정되어 있었다. manual로 설정하면 세션의 auto commit이 비활성화되어 커밋 또는 롤백으로 트랜잭션을 직접 종료해 주어야 한다.
나는 로컬에서 slave DB에 접속하여 DDL 수행 대상 테이블에 카운트 쿼리를 수행했었는데 이때 트랜잭션을 종료해 주지 않아 metadata lock을 계속 점유하고 있었던 것이다. 그래서 master DB에서는 지연 없이 정상적으로 DDL이 수행될 수 있었고 slave DB가 동기화되는 과정에서 slave SQL의 DDL이 대기하면서 복제 지연이 발생했고 애플리케이션에서는 커넥션 반환이 지연되고 풀에 가용한 커넥션이 부족하여 임계치까지 생성하게 되면서 활성 커넥션이 증가한 것이다.
결국 slave DB에 접속하는 커넥션을 줄여보고자 로컬 데이터베이스 클라이언트의 모든 커넥션을 종료시켰던 것이 장애 발생 원인을 제거하는 행위였고 커넥션을 종료하여 metadata lock을 점유한 세션이 종료되면서 서비스가 정상화되었던 것이다.
slave session - 1
1
2
3
4
-- Datagrip transaction option : Manual (auto commit 비활성화)
SELECT COUNT(*)
FROM howser_membership.contract; -- shared metadata lock 획득
master session
1
2
ALTER TABLE howser_membership.contract
ADD INDEX contract_group_srl_index(group_srl);
slave session - 2
1
2
3
4
5
-- Datagrip transaction option : Manual (auto commit 비활성화)
SELECT *
FROM howser_membership.contract
WHERE group_srl = 'grp240100003'; -- shared metadata lock 획득 대기
slave session - 3
1
2
3
4
5
-- Datagrip transaction option : Manual (auto commit 비활성화)
SELECT *
FROM howser_membership.contract
WHERE group_srl = 'grp240100003'; -- shared metadata lock 획득 대기

slave_sql(DDL), slave session - 2, 3은 slave session - 1이 점유 중인 shared metadata lock이 해소될 때까지 대기한다.
slave session - 1
1
commit;

대기 중이던 slave session - 2, 3이 shared metadata lock을 획득하여 select 쿼리가 수행되고 DDL은 여전히 대기한다.
slave session - 2
1
commit;

slave session - 2가 트랜잭션을 종료해도 slave session - 3가 shared metadata lock을 여전히 점유 중이므로 DDL 대기한다.
slave session - 1
1
2
3
4
5
-- Datagrip transaction option : Manual (auto commit 비활성화)
SELECT *
FROM howser_membership.contract
WHERE group_srl = 'grp240100003'; -- metadata lock 획득 대기

slave_sql(DDL), slave session - 1은 slave session - 3이 점유 중인 shared metadata lock이 해소될 때까지 대기한다.
slave session - 3
1
commit;

slave session - 3가 트랜잭션을 종료하면 shared metadata lock이 해소되고 대기 중인 DDL이 exclusive metadata lock을 획득하여 수행을 마친 다음 slave session - 1에서 shared metadaata lock을 획득한다.
메뉴얼에서는 metadata lock 획득을 대기하고 있는 세션이 여러 개인 경우 DDL의 우선순위가 높다고 언급하고 있다. 하지만 위의 예시를 보면 락을 점유하고 있는 트랜잭션이 종료된 후 share metadata lock 획득을 대기하고 있던 세션 2,3이 더 오래 대기한 DDL보다 먼저 획득하는 것을 볼 수 있다. 여러 번 테스트해 보아도 동일하게 동작했는데 아직 왜 이렇게 동작하는지는 메뉴얼에서도 언급된 내용이 없어서 파악하진 못했다.
Footer
innodb 스토리지 엔진에서 처리하는 락이나 online DDL에 대해서는 알고 있었지만 데이터베이스 엔진에서 처리하는 metadata lock에 대해서는 무지했고 Mariadb의 동시 요청 처리에 대해서 깊게 이해하지 못한 상태에서 운영 중에 DDL을 수행하면서 장애를 맞게 되었다.
이때까지 metadata lock에 대해서 인지하지 못한 상태로 운영 중에 DDL을 수행한 경험은 여러 번 있었지만 동일한 장애를 경험하지 못했던 이유는 데이터베이스 클라이언트에서 세션의 auto commit을 활성화한 상태로 사용해왔기 때문인 것 같다.
장애를 경험함으로써 알지 못했던 중요한 것들을 배워갈 수 있는 좋은 경험이 되기는 했지만 불편을 겪은 고객들과 전사 직원들에게 너무 죄송스러웠고 아무런 질책 없이 잘 대응해 주고 오히려 격려해 준 팀원들에게 너무 죄송하고 감사한 마음이 들었다.
이번에 장애를 내면서 나의 잘못으로 인해 개발팀이 더 장애를 두려워하게 되고 경직되게 될까 봐 걱정이 들기도 한다. 무조건 피하고 두려워하기보다는 정확한 원인을 파악하여 동일한 장애가 다시는 발생하지 않도록 예방책을 찾아야 한다고 생각했고 팀원들이 볼 수 있도록 사내 컨플루언스에 장애 회고록을 작성했다.
개발자로 경력을 쌓아간지는 이제 5년차인데 1~2년차 이후로 장애를 내본 경험은 이번이 처음이다. 그러다 보니 부끄럽지만 주변에서 장애를 내는 사람들이 꼼꼼하지 못하고 조심성이 없는 사람이 아닐까라는 생각을 하며 자만했던 적도 있다. 정작 그게 내가 되어보니 본인 나름에는 확신을 가진 상태에서도 실수를 할 수 있다는 생각이 들고 굳이 누군가 질책하지 않아도 본인 스스로가 가장 부끄럽고 죄송스러운 마음이 들기 때문에 질책보다는 격려를 말을 건네주어야겠다는 생각이든다. 그리고 가장 중요한 것은 겸손한 태도와 동일한 장애가 발생하지 않도록 내가 가장 노력하는 것이다.